Бугаенко Н. Н., Горбань А. Н., Попова Т. Г., Садовский М. Г.
Институт вычислительного моделирования СО РАН, 660036 Красноярск, Акадегородок; Институт биофизики СО РАН, 660036 Красноярск, Акадегородок
Не приходится ожидать,
что генетические тексты могут быть интерпретированы так же, как
тексты человеческого языка; едва ли можно вкладывать в генетические
тексты смысл, аналогичный смыслу человеческих текстов. Выходом
здесь может быть определение смысла генетического текста как его
отличие от случайного. Обычно исследование неслучайности генетических
текстов проводится путём их сравнения со случайными (модельными)
последовательностями, а само сравнение делается с помощью каких-либо
критериев или статистик. Нами развит подход, основанный на изучении
распределений слов (малых фрагментов), встречающихся в исходном
тексте: частотного словаря (ЧС). Будем рассматривать только связные
последовательности и их фрагменты. ЧС - это множество всех слов
(подпоследовательностей) заданной длины
q, встречающихся
в изучаемой последовательности, вместе с указанием их частот.
Информационное содержание генетических текстов определяется с
помощью восстановления ЧС большей толщины (содержащих более длинные
слова) по ЧС заданной длины; такое восстановление, как правило,
неоднозначно; случай однозначного восстановления изложен в литературе.
В случае неоднозначного восстановления восстановленным предлагается
считать такой ЧС (толщины
q+1), который обладает наибольшей
энтропией. В этом случае частоты такого ЧС могут быть вычислены
по частотам (реального) словаря толщины
q. Восстановленный
ЧС является максимально неопределённым среди всех тех, которые
могут дать (реальный) словарь толщины
q. Тем самым, отличие
реального текста от случайного может быть установлено вычислением
условной энтропии реального ЧС относительного восстановленного
(до той же толщины):
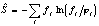 ,
или
,
или 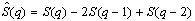 ,
,
здесь fi
- частоты реального ЧС, а ji
- частоты восстановленного. Условная энтропия принимает нулевое
значение, если мы имеем бернуллиевую последовательность; кроме
того, для достаточно длинных слов частоты восстановленных словарей
и частоты словарей, по которым велось восстановление, совпадают
(и равны 1/N, где N - длина изучаемой последовательности),
и условная вероятность снова обращается в нуль. Нами были проанализированы
нуклеотидные последовательности различных организмов; исследовались
как последовательности зрелых мРНК, кодирующих тот или иной белок,
так и отдельные фрагменты последовательностей ДНК, главным образом,
экзоны и интроны, на предмет их отличия от случайных последовательностей.
Установлено, что максимальное отличие ЧС реальных генетических
текстов наблюдается для слов длины 4 и 5. Для ЧС толщины 5 и выше
начинают сказываться эффекты конечности исходного текста, и уровень
отличий от случайных текстов опять падает.